
Decision Tree 란?
일련의 분류 규칙을 통해 데이터를 분류하고 회귀하는 지도 학습(Supervised Learning) 모델이다.
데이터의 모양은 Tree Structure로 나타내기 때문에 Decision Tree라고 부른다.


Decision Tree Induction Algorithm
Hunt's Algorithm
CART
ID3, C4.5, C5.0
SLIQ and SPRINT
Decision Tree는 Attribute 속성과 어떻게 의사결정을 몇개로 나눌 것인지에 따라 다르게 형성할 수 있다.
Attribute types : Binary, Nominal, Ordinal, Continuous
Split way : 2-way split, Multi-way split
Nominal Attributes

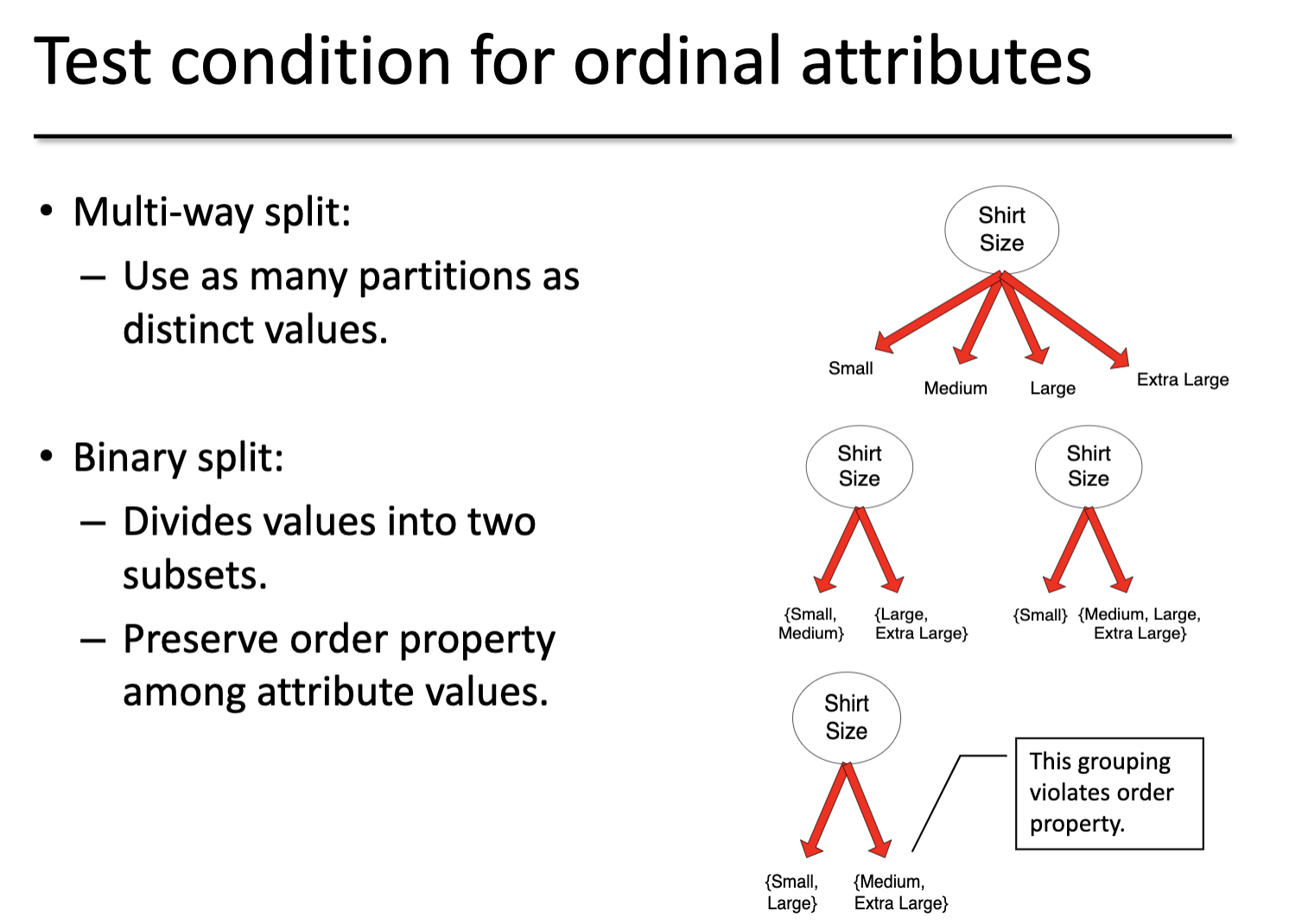
Ordinal Attribute
Continuous Attributes

Continuous Attributes Splitting
Discretization
Static
Dynamic
Binary Decision
Best Split Decision Tree
Gender : 2개의 가능성, C0은 1 ~ 10, C1는 11 ~ 20를 나타낸다.
개당 10개의 Record이며, 예를 들어 Gender, C0: 6 는 C0에서 Male이 6개라는 의미이다.

Purity, Impurity란? (불순도)
분배가 잘이루어 져있는지 판단하는 값이다.

좋은 Split 찾는 방법?
Splitting 전 상태인 P(Before)의 불순도를 측정하고, Splitting 이후의 상태인 M(After)의 불순도를 계산한다.
Highest Gain = P - M

Node Impurity(불순도) 계산 방법이란?
GIni, Entropy, Emisclassification Error 3가지가 있다.

Gini Index란?
Population Diversity를 측정한다.
예제


가장 좋은 Splitting 상태는? 첫번째 Multi-way split 다. Gini 값이 가장 작기 때문에 가장 잘 Split한 것을 알 수 있다.

Impurity(불순도) 측정 방법2 : Entropy

분류를 기반으로한 Decision Tree의 특징
장점 :
- 구조 생성 비용이 적다.
- 모르는 Records를 분류하는 것이 매우 빠르다.
- 사이즈가 작은 트리의 해석이 쉽낟.
- 잡음(Noise)에 강하다
- 중복되거나 관련없는 Attributes를 쉽게 핸들링할 수 있다.
단점 :
- 그리디 접근이기 때문에 항상 최적으 트리를 만드는 건 불가능하며, 많은 공간을 차지한다.
- Attributes간의 상호관계를 다루지 않는다.
- 각각의 결정 경계는 하나의 Attribute만 포함한다.
Overfitting이란? (과적합)
데이터에 대한 학습을 과하게 시행하여, 데이터에 대한 오차가 증가하는 현상이다.
Classification Errors : Training Errors, Test Errors, Generalization Errors
Underfitting : 모델이 너무 단순할때 훈련과 테스트 에러가 커진다.
Overfitting : 모델이 너무 복잡할때, 훈련에러가 작아지지만 테스트 에러는 커진다.
만약 훈련 데이터가 Under-representative하다면, 노드의 숫자가 늘어알때 테스팅 에러는 증가하고, 훈련 에러는 감소한다.
하지만, 주어진 노드 개수에서 훈련 데이터를 늘리는 것은 훈련, 테스트 에러들 사이의 차이를 감소시킨다.

'AI Master Degree > Data Mining' 카테고리의 다른 글
| Classification Regression (0) | 2021.10.29 |
|---|---|
| Chap. Bayesian Classifiers (0) | 2021.10.22 |
| Midterm Preparation : Data Mining (0) | 2021.10.14 |
| Chapter 3. Data preprocessing이란? (0) | 2021.10.12 |
| Chapter 2. Data 타입이란? Missing value란? Outliers란? (Data Mining) (0) | 2021.10.12 |