
Aggregation
Sampling
Dimensionality Reduction
Feature Subset Selection
Feature Creation
Discretization and Binarization
Attribute Transformation
Aggreation이란?
두개 혹은 세개 이상의 Attribute, Object들을 결합하여 하나의 Attribute, Object를 만드는 것이다.
목적
- Data reduction : Attributes, Objects의 수를 줄일 수 있다.
- Change of scale : 규모를 변경하는데, 도시들을 지역이나 나라로 혹은 일을 주, 월, 년으로 수정한다.
- More Stable data : 변동성이 적은 데이터로 만들 수 있다.

Sampling이란?

Data Reduction에 자주 사용되는 방법이며, 사전조사와 마지막 데이터 분석시에도 자주 사용된다.
Sampling을 사용하는 이유는 전체 데이터 집합을 사용하는 경유 시간과 비용이 너무 소요되기 때문이다.
Sampling을 사용할때 핵심 원칙은 Sample이 전체 데이터의 Sample이 대표적이거나,
기존의 데이터 집합과 같은 속성들을 가지고 있을때 사용하는 것이 효과적이다.
Types of Sampling이란?
- Simple Random Sampling : 동일한 확률을 통해 아이템을 선택하여 진행
- Without Replacement : 각 아이템을 선택할때, 모집단에서 제거
- With Replacement : 선택된 아이템은 모집단에서 제거되지 않으며 같은 객체가 여러번 선택 될 수 있음
- Stratified Sampling : 여러 파티션들로 데이터를 쪼개고, 각각의 파티션에서 임의의 샘플들을 선택
각각의 10개로 구성된 그룹들에서 최소 한개의 객체를 선택할때 Sample Size는 필수다.
Dimensionality Reduction란?
데이터를 다루기 전에, Curse of dimensionality, 차원의 저주를 피하기 위해 사용하는 데이터 처리 방법이다.
Data Mining 알고리즘을 활용하여 데이터 처리시, 시간과 메모리의 요구량을 줄일 수 있다.
데이터를 시각화 하는 것이 쉬워진다.
관련없는 특징들을 제거하거나 노이즈 데이터를 줄이는데 도움을 줄 수 있다.
Principal Component Analysis란?
차원의 크기를 줄이기 위해 PCA(주성분 분석)을 이용하여 특징들을 줄일 수 있다.
데이터의 분산(Variance)를 최대한 보존하고, 서로 직교하는 Principal axis를 찾아, 높은 차원에서 낮은 차원으로 Projection 하여 차원을 줄이는 방법이다.
e는 Eigenvaectors를 의미하며 이것을 찾는 것은 Principal axis를 찾는것과 같다.
아래 그림처럼 e에 직교하게 데이터들을 투영(Projection)하여 PCA를 완성한다.
3차원에서 2차원으로 데이터들을 Projections시 아래 그림과 같은 데이터가 출력된다.

- 그 외로 중복되거나 관계 없는 특징들을 다뤄 데이터의 차원을 줄일 수 있다.
- 또한, 새로운 Attributes를 생성하여, 중요한 정보를 알아내어 기존의 Attributes보다 효율적으로 적용가능하다.
Feature Extration(특징 추출), Feature Construction(기능 구성), Mapping data to new spae(새로운 공간에 매핑)
Discretization 이란? (이산화)
연속적인 속성을 숫자 속성으로 변환하는 과정이다. 이과정은 작은 수의 카테고리들에 잠재적으로 무한한 수의 값들을 매핑한다. 이 Discretization 은 보통 분류에 많이 사용된다. 많은 Classificatino 알고리즘들은 독립적인 변수들, 종속적인 변수들이 적은 값들을 가지고 있을때 원활하게 적용된다.
Unsupervised Discretization이란?
데이터 값들 안에서 경계를 찾는 방법

Supervised Discretization이란?
클래스 라벨들을 이용하여 경계를 찾는 방법
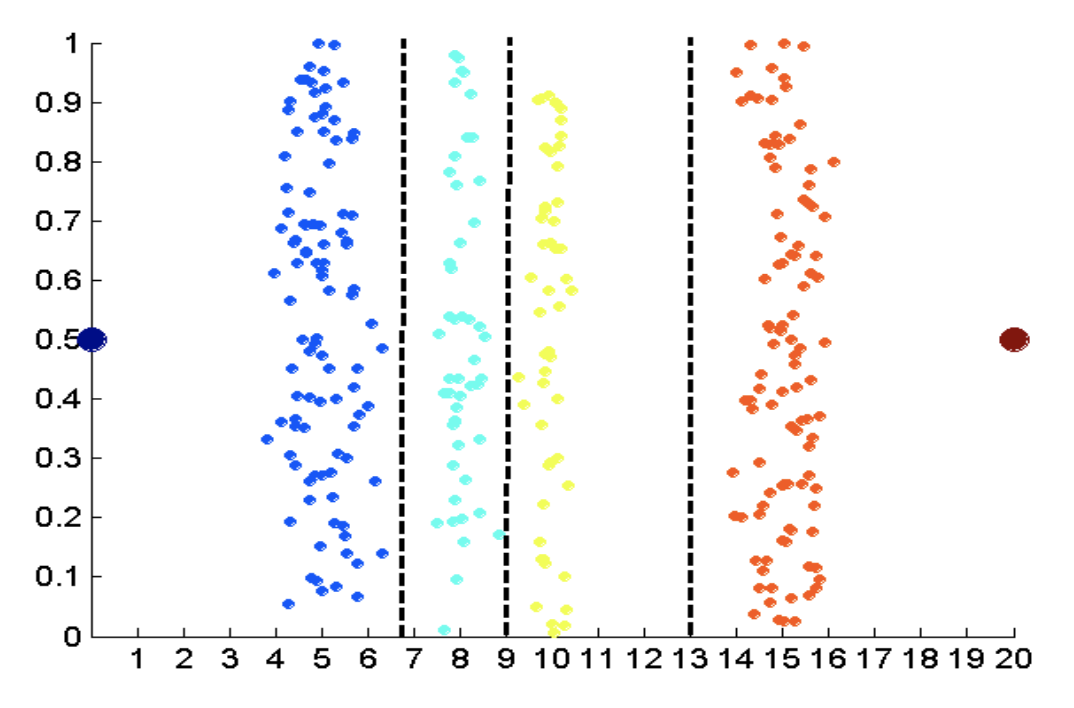
1. Equal Interval : 거리의 값을 경계의 개수로 나누어 일정하게 경계를 나누는 방법

2. Equal Frequency : 분포되어 있는 값들의 개수를 확인하여 많이 몰려있는 쪽으로 경계를 나누는 방법

3. Clustering : 특정(클러스터링) 알고리즘을 사용하여 경계를 나누는 방법
Binarization이란?
연속적이거나 범주를 가진 속성을 하나 이상의 이진 변수로 매핑하는 방법이다. 연관 분석에서 일반적으로 사용되며, 연속형 Attribute > 범주형 Attribute > 이진형 속Attribute성으로 변환한다. Association Analysis(연관 분석)는 Asymmetric Binary Attributes가 필요하다.
'AI Master Degree > Data Mining' 카테고리의 다른 글
| Chap 7. Decision Tree 결정 트리 (0) | 2021.10.20 |
|---|---|
| Midterm Preparation : Data Mining (0) | 2021.10.14 |
| Chapter 2. Data 타입이란? Missing value란? Outliers란? (Data Mining) (0) | 2021.10.12 |
| Chapter 1. Data mining이란? (0) | 2021.10.12 |
| Data Mining 기본 용어 정리 (0) | 2021.10.11 |