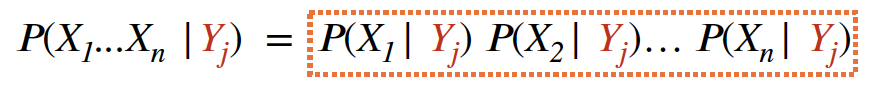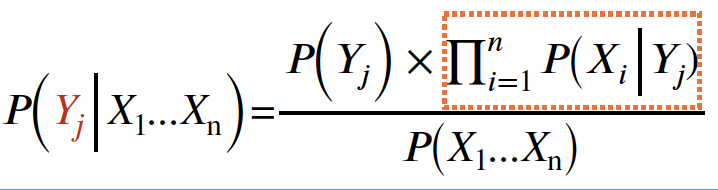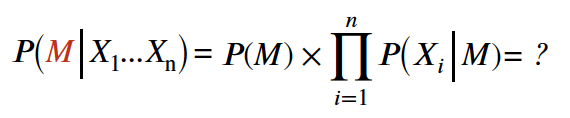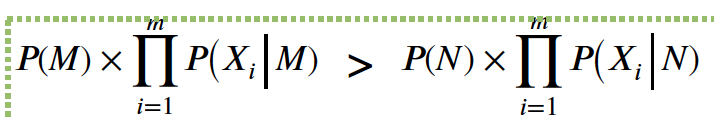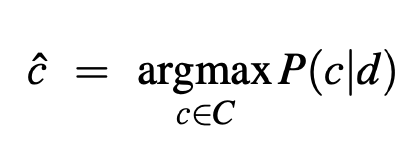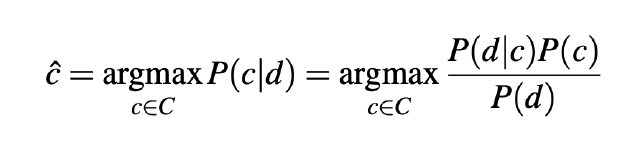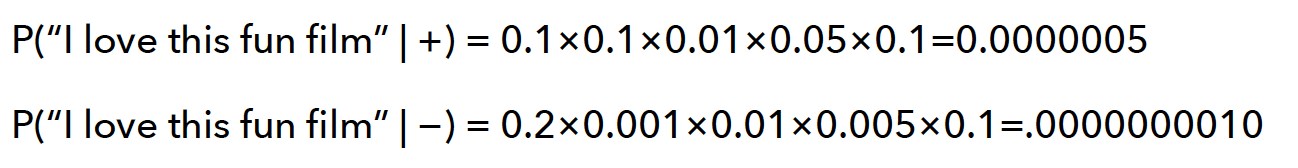Machine Learning 이란?
- 머신 러닝 분야는 다음과 같은 질문에 답한다.
- 경험과 함께 자동으로 개선되는 컴퓨터 시스템을 어떻게 구축할 수 있으며, 모든 학습 프로세스를 지배하는 기본 법칙은 무엇인가?
- 일반적인 유형의 Machine Learning 문제
- Classification (분류) [라벨/카테고리 예측]
- Regression (회귀 분석) [값 예측]
- Clurstering [유사한 항복을 함께 그룹화]
- ML 의 주요 유형
- Supervised Learning: Agent 가 입출력 Pair (쌍) 을 관찰하고(훈련) 입력에서 출력으로 매핑하는 기능을 학습
- e.g. Agent 는 "자동차" 또는 "인간" 으로 표시된 여러 이미지에 대해 훈련을 받고 결과 모델을 사용하여 Agent 가 이전에 보지 못했던 새로운 이미지를 라벨링 할 수 있다.
- Supervised Learning 에서는 레이블이 지정된 예가 포함된다는 점에 유의한다.

- N 개의 예제 입출력 쌍이 있는 훈련 세트 (x1, y1), (x2, y2), ..., (xN, yN)
- 여기서 각 쌍은 알 수 없는 함수 y = f(x)
- 함수 f 에 가까운 가설이라고 불리는 함수 h 를 알아내야 한다.
- 이상적으로 h(xi) = yi 라는 h 를 찾기 원하지만, 종종 가능하지 않기 때문에 일반적으로 h(xi) 가 yi 에 가까운 최적의 함수를 찾아야 한다.
- 훈련 세트에 가장 적합한 h 를 찾는 것보다 더 중요한 것은 보이지 않는 예시를 얼마나 잘 생성해내는 것이다.
- Unsupervised Learning: Agent 는 명시적인 피드백 없이 입력(데이터) 에서 패턴을 학습한다.
- e.g. 사용자를 클러스팅하여 "쿠폰을 20% 할인 받을 경우 더 많은 물건을 구입할 것 같다." 와 "만약 그들이 같은 종류의 두 번째 물건을 40% 할인된 가격에 사면 더 많은 물건을 사려고 한다."
- Reinforcement Learning: Agent 는 자신의 Action 에 대한 보성과 처벌을 사용하여 학습한다.
- 보상을 극대화하거나 처벌을 최소화하기 위해 향후 조치를 변경하는 방법을 파악한다.
- Navie Bayes 란?
- 확률에 대한 일반적인 접근법
- 확률은 반복 실험후에 발견되며, 이는 평균 및 분산과 같은 확률 분포의 실제 Parameters 를 찾는 데 도움이 된다.
- Bayesian 접근법
- Bayesian 통계학에서 확률은 가설에 대한 믿음의 정도를 측정하고 새로운 증거를 기반으로 갱신된다.
- 확률 A 의 P(A) 는 A 에 대한 초기 믿음의 정도이며, A 의 Prior probability 라고 한다.
- e.g. P(Meningitis) = 0.00002
- B 가 참이라는 것이 주어지고 그것을 알고 있을 A 의 확률, P(A | B) 는 B 가 참이라는 것을 통합한 후의 믿음의 정도, Posteriror probability 이다.
- e.g. P(Meningitis | Stiff Neck) 목이 뻣뻣한 환자인데, 뇌막염일 확률이 얼마나 되는가?
- 두 개 이상의 변수의 Joint Probability
- Joint Probability 는 두 변수 A 와 B, (e.g. P(A, B)) 는 A 에 대한 특정 값이 B 의 특정 값과 동시에 발생할 확률 이다.
- 일반인 중 한사람이 7 feet 키와 100 pound (A 는 키, B 는 몸무게) 둘 다 만족할 확률은 얼마인가?
- 일반인 중 80 세 이상 치매 (A 는 나이, B 는 치매 없음) 가 없을 확률은?
- 위의 내용은 두 개 이상의 변수들에도 적용된다.
- Joint Probability Distribution 이란?
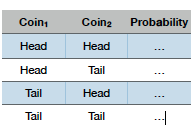
- 예를 들어 동전 두개를 던졌을때 (Coin1 = head, Coin2 = head), (tail, tail), (head, tail), (tail, head) 들 중 하나가 나올 수 있는 이벤트이다.
- 이러한 네 가지 결과는 각각 연관 확률을 가지고 있다.
- 또한 확률의 집합은 두 변수의 Joint Probability Distribution 이다.
Bayesian Classification 이란?
- Classification 문제를 해결하기 위한 Probabilistic 프레임 워크이다.
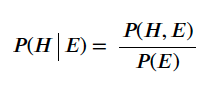
- Conditional Probability 조건부 확률: E 가 주어졌을때의 H 의 확률
- 분자는 H 와 E 의 Joint Probability 이다.
- 분모는 E 의 사전 확률이다.
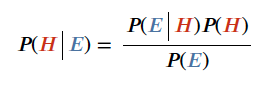
- Bayes Theorem
- H 는 가설이라고도 하며, E 는 증거라고도 한다.
- 예시
- 의사는 뇌수막염 meningitis 가 목을 뻣뻣하게 만들 경우를 50% 라고 한다. P(S | M)
- 뇌수막염 환자가 발생할 확률은 50,000 분의 1 이다. P(M)
- 목이 뻣뻣한 환자의 사전 확률은 1 / 20 이다.
- 만약 환자가 목이 뻣뻣하다면 뇌수막염에 걸릴 확률은?
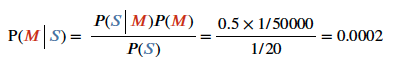
Conditional Independence 조건부 독립성 이란?
- 만약 C 가 주어졌을때, A 와 B 가 조건적으로 독립적이라면, C 가 주어졌을때 A 의 발생 여부에 대한 지식은 B 의 발생가능성에 대한 정보를 제공하지 않는다.
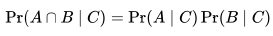
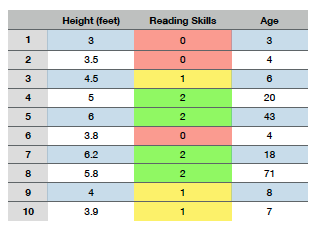
- 3살과 같은 특정 나이가 주어지면 독립적으로 읽기 능력과 키를 예측할 수 있지만, 나이가 없으면 키가 읽기 능력의 예측 변수 처럼 보이고 그 반대도 마찬가지로 보인다.
분류를 위한 Bayes Theorem
- 각 속성과 클래스 레이블을 랜덤 변수로 간주한다.
- 속성 (X1, X2, ..., Xd) 이 있는 레코드가 주어진다.
- 목표는 클래스 Yj (이 레코드가 속한 클래스) 를 예측하는 것이다.
- 특히 P(Yj | X1, X2, ..., Xd) 를 극대화하는 Yj 의 값을 찾는다.
- 즉, 이 Record 에 대해 가장 가능성이 높은 클래스 과제는 무엇인가?

- 데이터에서 직접 모든 클래스에 대해 P(Yj | X1, X2, ..., Xd) 를 추정할 수 있는가?
Naive Bayes 가 단 하나의 변수 대신에 변수 목록과 함께 작동하는 방법
- Bayes Theorem 적용
- 속성 Xi 들 사이에 조건부 독립성을 가정한다, 즉 클레스 Label 이 주어졌을 때 속성은 독립적이다.
- Y1 ... Ym 아래 최대 값을 얻기 위해, 테스트 샘플을 클래스 Yj 로 분류한다.
- 클래스 (Yi) 는 가장 큰 Nominator 를 얻기 위한 가장 좋은 클래스이다.
- 모든 Xi 와 Yj 로 조합된 P(Xi | Yj) 는 Training Data 로 계산될 수 있다.
- Naive Bayes 분류 예제
- 우리가 예측을 필요로하는 테스트 레코드
- A: X1 ... Xn 의 속성 세트
- M: Mammals (포유류)
- N: Non-mammals
- 위 테스트 레코드 대한 예측 클래스는 M 혹은 N 인가?
- 아래 그림을 보자, Mammals 클래스를 기준으로 계산한다.
- 클래스가 Mammals 일때 테스트 레코드에 대해 Probability 를 계산하자.
- 우선 네 개의 컬럼의 속성들을 각각 계산해야한다.
- Give Brith (Mammals 일때 Give Brith 가 yes 일 확률)= 6/7
- Can Fly (Mammals 일때 Can Fly 가 no 일 확률) = 6/7
- Live in Water (Mammals 일때 Live in Water 가 yes 일 확률) = 2/7
- Have Legs (Mammals 일때 Have Legs 가 yes 일 확률) = 2/7
- M 이 주어졌을 때 속성들에 대한 확률을 구하려면 체인 률을 적용하여 네가지 속성에 대한 확률들을 모두 곱한다.
- P(X1 ... Xn | M) 은 6/7 * 6/7 * 2/7 * 2/7 = 0.06 이다.
- 이제 N 이 주어졌을 때 확률을 계산하자
- Given Brith (Non-mammals 일때 Give Brith 가 yes 일 확률) = 1/13
- Can Fly (Non-mammals 일때 Can Fly 가 no 일 확률) = 10/13
- Live in Water (Non-mammals 일때 Live in Water 가 yes 일 확률) = 3/13
- Have Legs (Non-mammals 일때 Have Legs 가 no 일 확률) = 4/13
- 모든 속성을 계산하면 P(N | X1 ... Xn) = 0.0042 가 된다.
- 즉, 위 테스트 레코드는 아래와 같은 결과를 가져온다.
- 테스트 레코드는 Mammals 클래스 로 예측할 수 있다.
Multinomial Naive Bayes Classifier 다항식 나이브 베이지안 분류기란?
- 하나의 텍스트 Document 를 Bag of words 으로 나타낸다.
- 여기서 각 단어들의 출현 빈도만 중요하다.
- 예측 클래스는 Document 가 주어졌을 때 클래스 C 집합 중, 가장 높은 확률 (Posterior) 이 가장 높은 클래스 이다.
- 베이지안 룰을 적용하면 다음과 같이 나타낼 수 있다.
- 위 식을 통해, 이전 Naive Bayes 유도와 마찬가지로 CNB 를 예측할 수 있다.
- 여기서는 이전 계산방법처럼 Conditional Independence 를 가정해야한다.
-
- Under-flow (언더 플로우) 를 방지하기 위해 로그 기반 계산을 사용한다. (n-gram 언어 모델에서 사용했던 것과 같은 방식이다.)
생성 분류기로써의 Naive Bayes
- Naive Bayes 는 Generative Classifier (생성 분류기) 이며, 클래스가 특정 입력 데이터를 생성할 수 있는 방법을 기반으로 모델을 구축한다.
- 클래스간의 차별화를 돕기 위해 기능을 학습하는 차별적 모델과 반대이다.
- 위의 공식은 먼저 P(c) 를 기반으로 클래스들을 샘플링한 다음에 P(d | c) 를 샘플링하여 문서를 생성할 수 있는 것을 의미한다.
- c 클래스가 주어졌을 때 단어의 likelihood (우도) 를 계산하기 위해서 클래스의 모든 document 들을 포함하는 하나의 document 로 취급한다.
- 그 다음, c 클래스에 속하는 모든 document 에서 단어가 발생하는 횟수를 document 의 단어 유형 수와 비교한다.
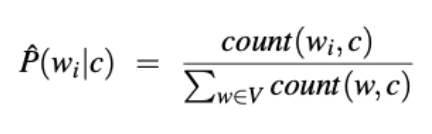
- 그리고 Smoothing 이 필요한데 여기서 Laplace 는 잘 작동한다.
- V 어휘는 모든 클래스에 걸쳐 모든 단어를 포함한다.
- 참고: NB (알 수없는 단어) 를 무시하기 위해 테스트 세트에서 해당 단어를 제거한다.
Sentiment Anaysis 최적화
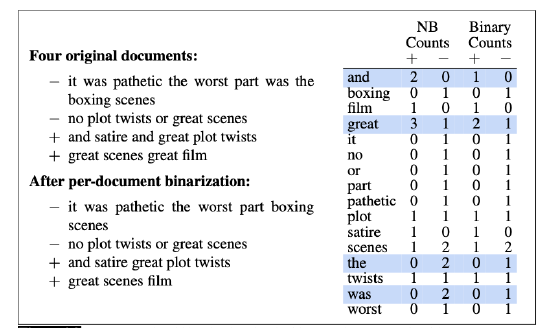
- Binary (Multinomial) Naive Bayes 는 하나 이상의 특정 단어가 나타나는 특정 클래스의 문서 수만 볼 뿐, 단어가 나타나는 횟수는 신경 쓰지 않는다.
- 이는 Sentiment Anaysis 에 효과가 좋다.
- 전과 같이 클래스에 대한 모든 문서를 하나의 문서로 연결하지만, 연결하기 전에 각 문서 내의 각 단어의 모든 중복을 제거해야한다. 그 이후 이전과 같이 모델의 교육을 진행한다.
- Sentiment Expression 에 중요한 Negations 보존
- Negates (부정 하는) 토큰에 있는 모든 단어에 NOT_ 이라는 단어를 앞에 붙인다.
- 예시: "Didn't like this movie, but I" 는 "Didn't NOT_like NOT_this NOT_movie, but I" 로 바꾼다.
- 부정적인 단어와 긍정적인 단어의 사전 사용 (특히 훈련 데이터가 충분하지 않은 경우)
Naive Bayes 의 다른 주요 응용 프로그램
- Naive Bayes 는 스팸 이메일을 탐지하는데 좋다.
- 일반적으로 언어적, 비언어적 특징도 추가한다.
- 이메일의 제목은 모두 대문자이다.
- "Million Dollars", "Urgent Reply' 과 같은 문구
- 메일 서버 라우팅 경로
- Language identification (언어 식별) - 텍스트의 특정 부분이 어떤 언어로 되어 있는지
Naive Bayes VS Language Models
- Naive Bayes 는 단어들에만 적용된다. (비언어적 특징과 반대)
- 텍스트에 모든 단어를 포함하는 것은 각 클래스에 대한 Unigram 모델과 같다.
- 특히 Naive Bayes 는 클래스에 따라 조건화된 모든 문장에 확률을 할당할 수 있다.