Language Models 이란?
- 단어들로 구성된 Sequences 에 Probabilities 확률을 할당하는 것을 의미한다.
- Language Model 이란 단어의 조합이 Sequence/String 에 포함될 Probability 가능성을 설명하는 확률 분포
- e.g. 영어에서 'Do I dare disturb the universe?' 가 likelihood 가 높은 반면에 'Universe dare the I disturb do' 는 낮은 수치를 가진다.
- Language Model 은 단어로 구성된 Sequence 들의 전체 Joint probability 분포를 획득한다.
확률 기본 개념
- P(Weather, Cavity) 와 같은 Joint probability distribution 은 모든 변수들 값의 조합들의 확률을 나타낸다.
- Probability model 은 도메인을 위한 모든 랜덤 변수들의 joint distribution 으로 결정되며, full joint probability distribution 이라고 한다.
- A set of variables 변수들의 집합은 각각 다른 것들에 영향을 끼치지 않는 독립적 성격을 가지고 있다.
- e.g. P(Wheather, Cavity)
- 독립변수의 Product 규칙: P(A, B) = P(A)P(B)
- 독립적이지 않은 변수의 Product 규칙: P(A, B) = P(A|B)P(B)

언어모델 응용
- 다음 단어가 무엇일찌 예측: 일반적으로 전자 메일 및 텍스트의 자동 완성에 사용
- 문장을 어떻게 더 변경할 수 있는 지에 대한 가능성을 예측: 철자 및 문법 수정에 사용
- 하나의 언어에서 다른 언어로 변역할때 가장 가능성 있는 변역을 찾기위해 pair of models 을 사용
- 선택 항목 중 답으로 가장 가능성이 높은 답을 찾을때 도움: 질문/답변 찾기에 사용
N-Grams 란?
- n-gram 은 n 개의 단어들에 대한 Sequence 이다.
- Unigrams (1-grams) 는 하나의 단어를 포함
- Bigrams (2-grams) 두개의 단어들의 Sequence (연속) 이다.
- Trigrams(3-grams) 세개의 단어들의 연속이다. 'the cat is'
- N-gram 은 n-grams 의 가능성을 예측한다.
- 모델은 예측하려는 단어 앞에 있는 n - 1 개의 단어들을 살펴본다.
- e.g. Trigram 은 첫 두단어 'the cat' 가 주어졌을 때 가장 가능성이 높은 단어를 예측하려고 시도할 수 있다.
기본 개념
- 임의의 변수 Xi 가 특정 값을 가질 확률은 P(Xi) 로 표시된다, 예를 들어 'the' 는 P(Xi = "the") 혹은 P(the) 로 표시한다.
- 연속적인 n 개의 단어들의 Probability, w1, w2, ... , wn 은 P(X1 = w1, X2=w2, ... Xn = wn) 으로 표현하거나 P(w1, w2, ... , wn) 으로 표현한다.
- Probability P(X1, X2, ... , Xn) 의 분해하는 방법은 Probability 의 Chain rule 를 사용하는 것에 기반한다.
- 단어들의 관점에서 P(w1 : n) = P(wk | w1 : k-1) 를 보면, w1 : k - 1 은 인덱스 1 부터 k - 1 인덱스 까지의 단어를 나타낸다.
- 이는, Sequence 에서 단어의 Probability 가 앞 단어들의 Sequence 에 따라 바뀌는 것을 의미한다.
N-gram 모델의 접근방식
- n-gram 모델은 마지막 몇 개의 단어를 사용하여 단어의 History/Sequence 를 근사값을 계산하고, 이 계산을 단순화한다.
- 만약 N 에 의해 n-gram 이 표시된다고 추측된다면, 우리는 단어의 Probability 를 추정할 수 있다.

- P(Wn | W1:n - 1) = P(Wn | n - N + 1 : n - 1)
- 위 식을 참고하여 예를 들어보면, trigram 모델 (N = 3) 에서 4 번째 단어 (n = 4) 에 대해 우리는 n - N + 1 = 4 - 3 + 1 = 2 를 얻는다. 따라서 식은 아래와 같아진다.
- 만약 Bigram 을 사용한다면 우리는 한 단어에 대해 다음과 같은 Probability 를 얻는다.
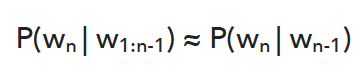
- Wn 의 확률은 이전 단어 Wn-1 에만 의존한다.
- 그리고, 단어 Sequence 의 Probability 는 아래와 같이 체인 룰을 적용한다.
- 위 계산식을 계산할때 Maximum Likelihood Estimation (MLE) 를 사용한다.
- 예를 들어 Bigram 시나리오에 대해서 계산할때 최대우도 측정법을 사용하여 Wn-1 로 시작하는 모든 Bigram 에 대해 Wn-1 이 이어지는 횟수 Wn : C(Wn-1Wn) 을 계산한다.
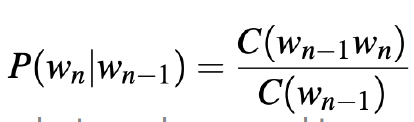
- 첫 번째 단어와 마지막 단어에 대한 Bigram 을 구성하기 위해서는 시작과 끝에 특별한 기호를 만들어야 한다.
- <s> 는 문장의 시작을 나타내고 <\s> 는 문장의 끝을 나타낸다.
- Trigram 에서는 <s> <s> 와 <\s> <\s> 를 사용한다.
계산 예시
- 세개의 문장이 corpus 에 다음과 같이 존재한다.
- <s> I am Sam </s>
- <s> Sam I am </s>
- <s> I do not like green eggs and ham </s>
- 각 probability 는 다음과 같다.
- P(I | <s>) = 2/3 = 0.67 문장 첫 시작에 I 가 있는가?
- P(Sam | <s>) = 1/3 = 0.33 문장 첫 시작에 Sam 이 있는가?
- P(am | I) = 2/3 = 0.67 I 가 존재할때 I 다음으로 am 이 오는가?
- P(</s> | Sam) = 1/2 = 0.5 Sam 이 있을때 마지막에 Sam 이 오는가?
- P(Sam | am) = 1/2 = 0.5 am 이 있을때 Sam 뒤에 am 이 오는가?
- P(do | I) = 1/3 = 0.33 I 가 있을때 I 뒤에 do 가 오는가?
- 만약 Bigram 모델을 사용한다 했을때 P("I am Sam") 의 확률은 다음과 같다.
- P("I am Sam") = P(I | <s>) * P(am | I) * P(Sam | am) * P(</s> | Sam)
- P("! am Sam") = 0.67 * 0.67 * 0.5 * 0.5 (문장의 시작과 끝을 포함한다.)
- 로그 기반 Probability 계산
- 작은 확률 값들을 많이 곱하면 Underflow 가 발생한다.
- Underflow 는 숫자가 너무 작어서 특정 컴퓨터 아키텍처에서 나타낼 수 없을 때 발생한다.
- 확률은 항상 0 ~ 1 범위이며 종종 n-gram 계산에서 0 에 매우 가깝다.
- 일반적으로 확률의 로그 계산을 하고 다시 확률로 변환한다.
- P("I am Sam") = exp(log(0.67 * 0.67 * 0.5 * 0.5)) = exp(log(0.67) + log(0.67) + log(0.5) + log(0.5))
- Product 의 Recall 은 개별 구성 요소의 로그 합계와 같다.
- N 이 N-gram 안에서 갖는 다른 값들의 Trade-off 들
- 단어들은 각각 다른 의미를 가진 다른 구절의 일부가 될 수 있는데, 짧은 n-gram 은 그렇지 않다.
- 예를 들어, 사업안에서의 'first quater earnings report' 그리고 스포츠에서 'fourth quater touch down passes' 와 같은 일반적인 문구를 처리하려면 4-gram 이 필요하다.
- 큰 값의 n 을 처리해야하는 경우 성능 문제가 발생한다.
- n-gram 모델에 근사치가 없을 때, 단어가 100,000 단어이고 길이가 40 인 문장으로, 각 단어를 어휘의 다른 모든 단어에 의존하도록 만든다면 100,000 ^ 40 = 10^200 의 매개변수를 추정할 필요가 있다.
- 위와 같은 조건으로 Trigram 을 사용한다면 100,000 ^ 3 = 10^15 로 더 나은 결과를 갖는다.




