
Distributional Hypothesis 분포 가설
- 분포 가설: 단어가 분포하는 방식과 의미 사이에는 연관성이 있다.
- 유사한 단어들은 (예시: "occulist 와 "eye-doctor") 는 유사한 환경/상황 (예시: "eye" 와 "exam") 에서 발생한다.
- 두 단어의 의미 차이는 그들의 "환경" 의 차이에 해당한다.
- 백터 임베딩은 (분포 가설과 백터 표현 접근법에 따라) 단어 분포에 기반한 단어의 학습된 표현이다.
Vector Embedding 벡터 임베딩
- 백테 임베딩에서 각 단어 또는 문서는 다차원 공간의 한 점이다.
- 임베딩은 한 공간에서 다른 공간으로 매핑하는 것이다 - 이 경우 단어에서 숫자 벡터로 변환한다.
- Sparse Embeddings (희소 임베딩) - 단어 수 및 동시 발생 (tf-idf) 을 기반으로 한다.
- 0 이 많이 포함되어 있어서 희소라고 말한다. (대부분의 단어는 다른 단어의 맥락에서 나타나지 않는다.)
- Dense Embeddings (고밀도 임베딩) - word2vec 임베딩과 같은 딥 러닝 네트워크에 의해 자동으로 학습된다.
- "Embedding" 이라는 단어는 종종 고밀도 임베딩만을 위해 예약된다.
Term-Document Matrix 단어-문서 메트릭스
- 모든 단어가 문서 말뭉치에서 추출되어 'vocabulary' 에 추가된다.
- 어휘의 모든 단어(용어) 를 행으로, 모든 문서를 열로써 행렬을 작성한다.
- 각 셀에는 특정 단어가 해당 문서에 나타는 횟수 (항 빈도) 가 포함된다.
- 문서 벡터를 비교할 때의 Intuition: 유사한 문서는 유사한 단어와 단어 수를 갖는 경향이 있으며, 따라서 유사한 열 벡터를 갖는다.
- 던어 벡터를 비교할 때의 Intuition: 유사한 단어들은 유사한 문서에서 발생하기 때문에 유사한 벡터를 갖는다.
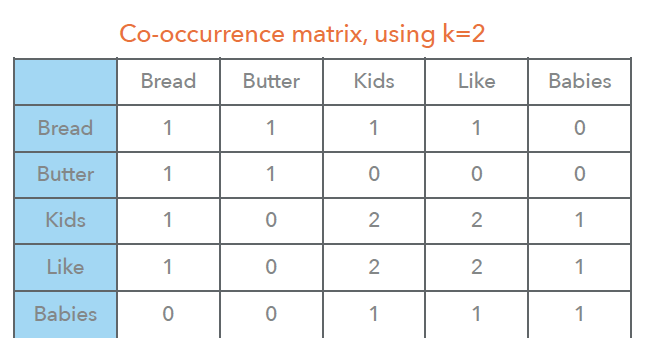
단어 임베딩을 생성하기 위한 Term-Term Matrix
- Skip-gram 모델: 서로 가깝지만 그 사이에 다른 단어가 있을 수 있는 단어를 세어 저장한다.
- 예를 들어, 한쌍의 단어 사이에 거리가 k 안에 있는 횟수
- Document1: Kids like bread and butter
- Document 2: Babies like kids
Weighting work 빈도 (가중치)
- 단어 Frequencies (빈도) 를 고려할 때 가중치를 도입하는 이유
- 매우 빈번한 단어는 다른 유형의 문서 ('the' 또는 'good' 과 같은 단어) 를 구별하는데 반드시 도움이 되지 않는다.
- 문서를 구별하는데 도움이 되는 단어를 강조해야한다. ('rocket' 과 'election' 는 Space 를 더 명확하게 나타낸다.)
- 접근법의 예시
- 용어 문서 행렬에서 추출된 단어 벡터의 용어 빈도-역 문서 빈도 (TF-IDF) Term Frequency-INverse Document Frequency
- 항 행렬에서 추출한 단어 벡터에 대한 Positive 점별 상호 정보 Positive Pointwise Mututal Information (PPMI)
TF-IDF
- TF = Term Frequency
- 주어진 문서에 단어 (term t) 가 나타내는 횟수 d
- 또는 용어가 나타나는 횟수를 문서의 단어 수로 나눌 수 있거나 이항식 일 수 있다.
- 예시: 단어가 문서에 나타나거나 나타나지 않는다.

- IDF = Inverse Document Frequency
- 말뭉치 (N) 의 문서 수를 특정 단어가 나타나는 문서 수로 나눈 값 (df_t)
- 단어가 제공하는 정보의 양 (말뭉치 전체에서 얼마나 희귀하거나 일반적인지) 를 반영한다.

- TF-IDF =

TF-IDF 개념
- 주어진 문서에서 Hig term frequency (높은 tf 값) 와 전체 문서 컬렉션에서 낮은 빈도 (높은 idf 값) 로 tf-idf 단위의 높은 가중치를 설정한다.
- TF-IDF 는 특정 문서 유형의 강력한 지표인 희귀 단어를 강조한다.
- (예: Medical content ('patient') vs 공간 탐사 내용 ('astronaut'))
- 문서를 구별하는데 도움이 되지 않는 일반적인 단어를 강조하지 않는다.
- (예: 'can' 이라는 단어는 Medical content 와 Space exploration content 를 강조하지 않는다.)
Pointwise 상호 정보
- PMI(Pointwise Mutual Information) 는 x 와 y 라는 두 사건이 우연히 발생하는 빈도

- (즉, 독립정인 경우) 와 관련하여 얼마나 자주 동시에 발생하는지를 측정한다.
- Natural Language Processing 에서 이벤트는 단어 w 및 컨텍스트는 단어 c 이다.

- P(w, c) 는 두 단어가 얼마나 자주 함께 관찰 되는지에 대한 값
- P(w)P(c) 는 두 단어가 각자 독립적으로 얼마나 많이 기대되는지에 대한 값
- PMI 는 두 단어가 우연히 발생한 단어보다 얼마나 더 많이 발생하는지에 대한 경우
- 일반적으로 Positive 값들만 PMI 에 사용한다. (Positive PMI or PPMI)

예제


Representing Documents 를 위한 단어 기반 임베딩 사용
- 문서 비교를 위해 tf-idf 와 PMMI 에서 생성된 단어 벡터를 어떻게 사용하는가?
- k 개의 단어 벡터들 (w1, w2, ... wk) 로 구성된 문서의 경우, 중심 문서 벡터 d 를 얻기 위해 단어 벡터의 평균을 취한다.
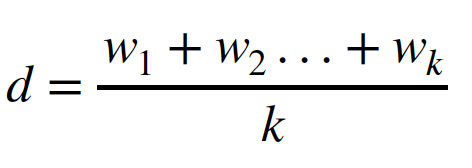
Vector Similarity
- Cosine Similarity 는 Document Similarity 를 계산하기 위한 메트릭중 가장 유명하다.
- 만약 d1 과 d2 가 두개의 문서 백터 라면

- 두 벡터 사이의 Cosine 은 단위 길이로 정규화하고 내부 곱을 취하는 것과 같다.
- 도트 (닷) 은 벡터 곲을 나타내고 ||d|| 는 벡터 d 의 길이이다.

- 두 벡터 사이의 코사인
- 두 벡터 코사인이 일치하면 1 (각도는 0 이다.)
- 일치하지만 반대 방향을 가리키는 경우는 -1 이다. (180 도)
- 직교할 때는 0이다. (90 도 직각)
Topic Modeling
- 확률론적 주제 모델
- 주제 모델링은 문서를 클러스터링하기 위한 Unspuervised 방법이다.
- 대규모 문서 말뭉치의 내용을 전반적으로 파악할 수 있다.
- 데이터 집합 k 에서 'topic' 의 수에 대한 매개 변수 k 를 지정한다.
- k 는 하이퍼 매개 변수의 예이다.
- (모델에 의해 훈련되지 않고 사용자가 지정한 매개 변수)
- 주제 모델링은 각 문서에 여러 Latent (잠재) / Hidden (숨겨진) 아이디어 / Themes / topics 들이 포함되어 있다고 가정한다.
- 각 주제는 알고리즘이 찾아내는 단어 분포로 특정지어진다.
- 이는 다시 각 문서에 포함된 해당 주제와 일치하는 단어 분포를 기반으로 한다.
'AI Master Degree > Natural Language Processing' 카테고리의 다른 글
| Logistic Regression 이란? (0) | 2022.10.10 |
|---|---|
| Model Evaluation란? 모델 평가란? (0) | 2022.10.10 |
| WORD AND DOCUMENT EMBEDDINGS 단어와 문서 임베딩이란? (0) | 2022.10.09 |
| Naive Bayes & Classification 이란? (1) | 2022.10.08 |
| Model Evaluation란? 모델 평가란? (1) | 2022.10.08 |