AI Master Degree/Natural Language Processing
Transformers 란? 트랜스포머란?
saurus2
2022. 10. 20. 06:45
RNNS의 문제점
- 긴 문장을 다루기 어렵다 - information loss (정보가 손실 된다.)
- 학습이 어렵다. - 학습이 길어지면 Gradient(경사도)가 사라진다.
- 이러한 문제점들 때문에 Recuurent Connection이 없는 트랜스포머가 개발이 되었다.
Transformer 구성요소
- 트랜스포머는 일련의 입력값들이 사용되며, 결과값은 입력 값의 길이와 같다.
- 예시: input(x1, ..., xn)와 output(y1, ..., yn)
- 트랜스포머는 트랜스포머 블록들을 Stack으로 구성한다.
- 각 트랜스포머는 간단한 Linear layers, Feed forward network layer, 그리고 self-attention layer들을 가지고 있다.

Self-attention이란?
- Self-attention은 트랜스포머 개발의 중요부분이다.
- Recurrent connections없이 임의의 큰 글에서 정보를 추출할 수 있다.
- 셀프 어텐션은 현재 단어와 다른 단어들을 비교하여 현재 단어의 관련성을 계산한다.
- 비교방법은 dot product(행렬 곱)을 사용하여 similarity score를 계산할 수 있다. e.g. [score(xi, xj) = xi . xj
- 점수가 높을수록 유사한 단어이다.

- Similarity 결과를 확률로 바꾸기위해 softmax 함수를 사용하여 score를 얻을 수 있다.

- 소프트맥스 함수에서 나온 결과값들은 입력 가중치들과 곱하고 모두 합하여 전체 결과 값을 만든다.

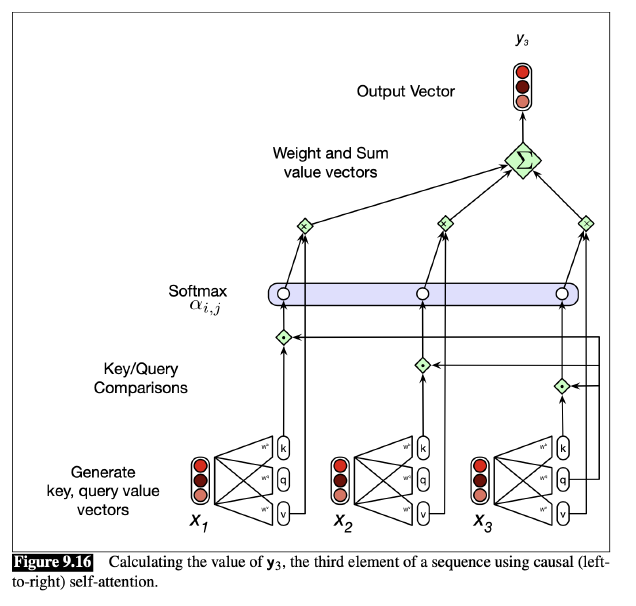
어텐션 계산 방법
- 각 입력 embedding은 3가지 역할을 가지고 있다.
- Query(Q): 현재 어텐션의 focus가 되는 경우 그리고 이전의 입력값들과 비교되는 경우
- Key(K): 현재 어텐션의 focus에 대한 이전 입력값들
- Value(V): 현재 어텐션의 출력을 계산하는 데 사용
- 트렌스포머에는 각 역할에 대한 각각의 가중치가 존재한다.

- 우리는 이 메트릭스들을 사용하여 입력 값을 3가지 역할로 나타내는 벡터로 만든다.

- 그러므로, 이러한 식을 가지게 된다.

- 또한 큰값들을 피하기 위해 스케일을 아래와 같이 계산한다.

- 여기서 dk는 키 벡터의 크기이다.
- 위 계산을 모든 데이터에 계산하면 아래 식과 같다.

- 그리고 N개의 레이어의 Self-attention 식은 다음과 같다.

- 메트릭스의 위쪽 파트 값들은 제거될 필요가 있는데, 쿼리 이후에 나오는 입력값들의 비교이기 때문이다.

- 참고: 대부분의 응용 프로그램들은 입력의 길이(토큰 수)를 전체 문서가 아닌 문단이나 페이지(문서 전체)로 제한한다.
트랜스포머의 기본 형상
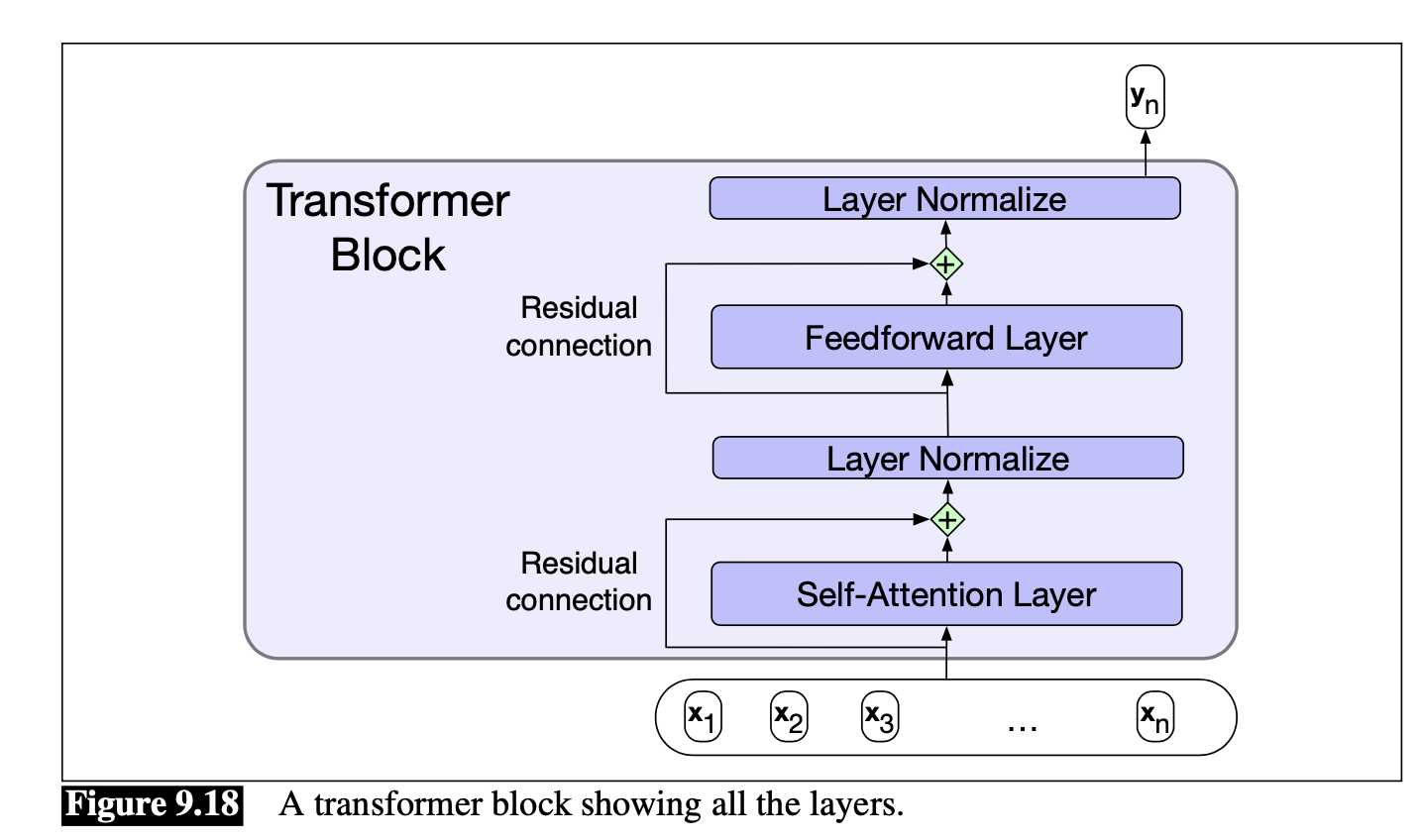
- 전체 그림을 보면 Residual Connection이 있는데 이는 학습의 퍼포먼스를 향상시킨다.
- 활성화와 Gradient는 레이어들을 넘는 것이 가능하다.
- 다음 레이어에 결과를 입력으로 전달하기 전에 레이어의 입력 벡터를 출력 벡터에 추가하는 것을 포함하여 구현해야한다.
- 그 후, 벡터는 정규화된다. 내부 layer 출력을 정규화하는 것은 Gradient 기반 훈련을 개선하는 방법이다.